Bookworm - Utility to download books via IRC
I read a lot. There are currently 245 books on my kindle collection. And yet, Amazon seems to be unable to provide me with a hassle-free way to buy books.
- They will not give me a link to download the books I pay for
- They will 'allow' me to use some convenience service to get the books 'synced' to my device, 'soon' after buying them. This can be in the range of minutes-to-hours.
- Books are riddled with nasty DRM, so making local backups is a chore (Using Calibre to de-DRM them) -- and I'm not risking it after the 1984 scandal.
My strategy for a few years has been to buy the e-book directly from author's
website if it is availalble in a DRM-free fashion.
If this is not the case, I'll buy the e-book via Amazon but download it from
a more convenient source -- irc channels.
I will not go into detail on how these channels work as there's plenty of information online already, but a quick summary is:
- Join an e-book channel
- Ask the indexer bot which bots have the book you want (
@search <whatever you want>) - From the results, pick a bot and ask it for the book.
This is less cumbersome than using Amazon's method for syncing books, but still annoying.
Designing a tool to handle this
The minimum requirements for a tool like this are:
- Communication over IRC (and DTCC file transfers)
- Unpacking and converting files that come in non-kindle formats
- Storing the resulting files
- Ease of querying
V1
In the initial version, I designed the system to work based on 'requests'.
I'd make a request to the service, which would spawn a thread and start to advance through the tasks.
- Set up an IRC Connection
- Wait 30 seconds (required by the channel)
- Request a book
- Get a DTCC message
- Connect to the DTCC endpoint
- Unpack files
- Convert files
- Store new status in local database
There was no way to resume a request that had failed half way through and it was quite opaque to debug as well.
On top of that, waiting a fixed 30s period was annoying as hell.
I decided to take these same requirements but split them into individual services. This'd make the code a bit easier to work with, get rid of the 30s wait time and allow me to resume a request later in case it had failed.
V2
This time I approached the problem as an event-based system.
Instead of a single process in charge of each request, the request gets split into logical parts and each part is handled by a different, small process.
Each process is listening to a message queue, waiting for tasks.
The integration point for these processes is done via message-passing over redis queues.
'Resuming' a task is the same as putting a message in the queue of the process that failed.
Overall architecture
The initial summary of the required steps to download a book included asking the indexer bot who has what you are looking for; but we can do this step preemtively by asking each bot for their entire book list and storing it locally.
If we do this, we can expose a (fast) API endpoint that we can use to search.
One service per task. Tasks:
- API to receive commands
- IRC client to request books
- DTCC client to fetch books
- Unpack/Convert fetched books
- Serve fetched books over HTTP
Services
Each service is listening to a dedicated queue for tasks, after executing these the result will be passed on to the next queue.
The end result of a user request is a kindle-compatible, drm-free file that can be fetched over HTTP.
If there's a need to store a blob, it will be stored in a local S3 instance (minio).
The metadata for each job is stored with a TTL of 5 days in redis. Every time a job progresses through the pipeline, its metadata is updated to reflect the current state.
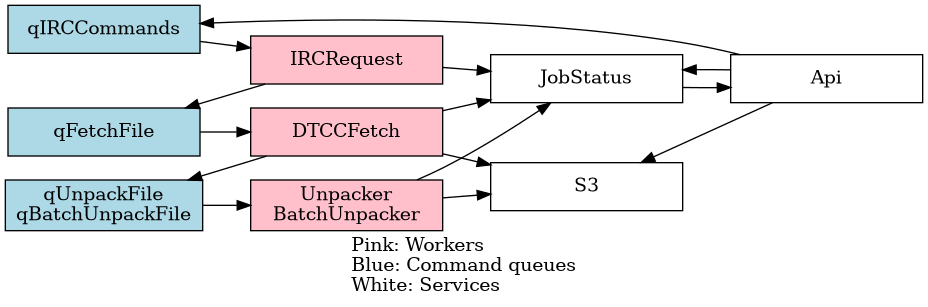
- API
- Input: Fetch request
- Output: (To user) fetch request id for status tracking
- Output: (To system) fetch request
- Input: Fetch status query
- Output: (To user) fetch status
- IRCRequest: Connects to an IRC channel and
- Input: Book download request
- Output: DTCC parameters to fetch said book
- DTCCFetch
- Input: DTCC parameters
- Output: S3 key containing the fetched files
- Unpacker
- Input: S3 Key to books (compressed, in variable formats)
- Output: S3 key to uncompressed, mobi-formatted book
Web UI
The web UI exposes the 3 main aspects of the service:
- Book Search/Fetch
- Status of 'recent' tasks
- Available books
The web UI had 2 hard constraints that had to be met:
- Searching/Fetching a book should be easy on mobile
- The page to download an available book should work on the kindle's browser.
Conclusion
I am reasonably happy with what I've built. It meets my criteria and it is very convenient when I finish a book in a saga and want to keep going but I don't have the next book on the kindle yet.
It does make me unreasonably angry that the process of acquiring the files for books I pay for is so cumbersome that it warrants a custom solution.
You can find the code here
 RSS feed
RSS feed